

The Need for NetSecOps
Traditionally Network Operations and Security Operations teams have operated in their own silos mainly due to different goals. Network teams focus on facilitating access to information and devices, while security teams focus on limiting access to information and devices. This results in disparate tools and leads to blind spots within the network which bad actors can exploit. Furthermore, if/when a threat is detected, it can take days/weeks/months to investigate and remediate the issue due to lack of communication and collaboration between the two teams. NETSCOUT’s NetOps and SecOps tools and technology improve this collaboration.
Netscout’s Omnis Security Platform is based on a foundation of visibility without borders to provide a single source of smart network derived data (Smart Data) for more efficient service assurance and cybersecurity. The Omnis Security platform gives both NetOps and SecOps the ability to view the same network-derived data, with different lenses, to collaborate and quickly act on that data to prevent further damage to the organization.
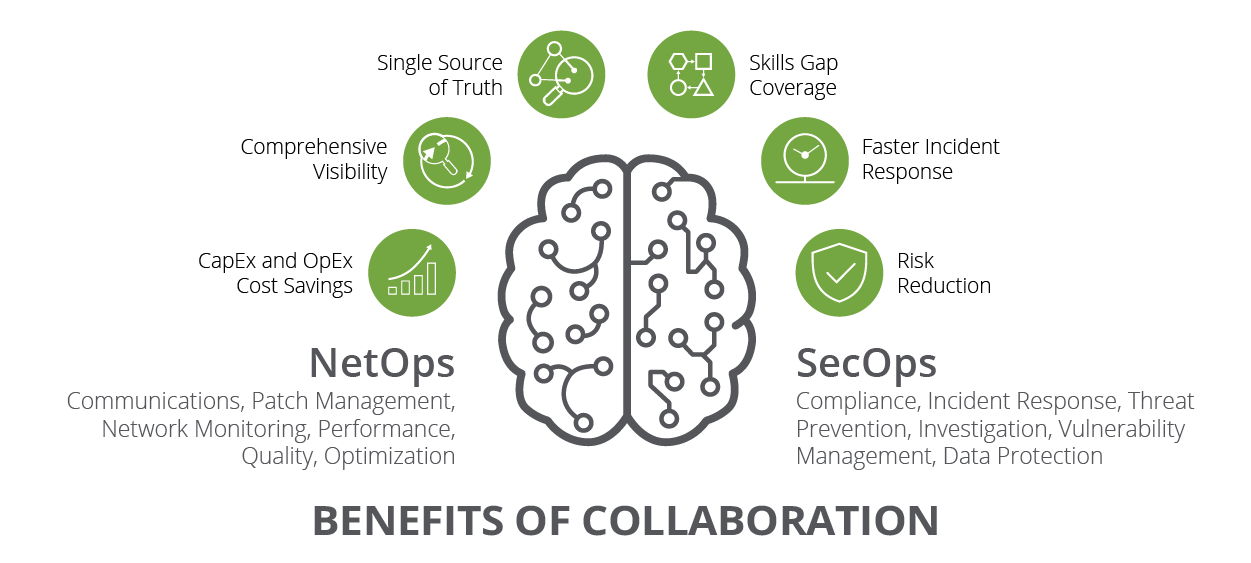
Benefits of our NetOps and SecOps Tools for Collaboration
Greater Visibility
Faster Response
Cost Savings
Talent Gap

A Double-Edged Sword
IT and security teams will be continuing their collaboration for the foreseeable future as work from home and hybrid work styles appear to be here to stay. This white paper focuses on providing a better understanding of the security and service assurance challenges that this new dynamic at the edge presents and what is necessary to address them.
Resources
Related Pages

Network Detection and Response

Omnis CyberStream and Omnis Cyber Intelligence NDR Platform

Network Observability
